Пару-тройку месяцев назад мне нужна была идея для проекта и в итоге решил написать webmail клиент с gmail-подобными цепочками писем. Это то чего мне не хватает, и чем бы пользовался регулярно на ежедневной основе.
Mailr на ранней стадии разработки, еще очень многое предстоит сделать.
Сейчас есть демо концепта, которое довольно быстро работает. Из того что сделано большая часть не очень видна, так как она связана с IMAP общением, отложенной синхронизацией, парсингом писем, а видимая часть – немного рабочего интерфейса. Можно послать письмо на demo[at]pusto.org и оно появится в Inbox.
Рабочее название проекта Mailr. Код на github.
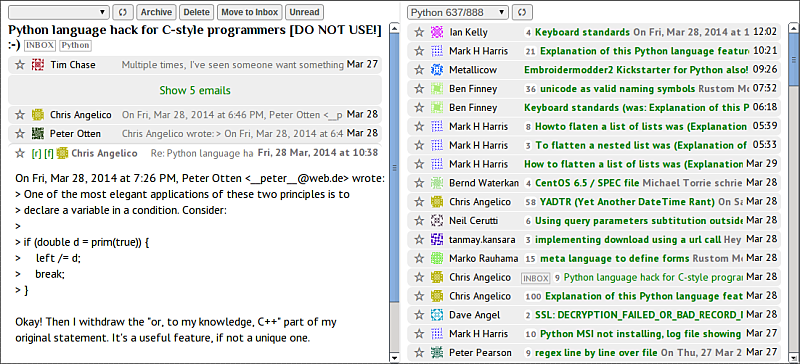
Мое видение первой версии
Mailr будет иметь быстрый и удобный веб интерфейс, которым будет удобно пользоваться на небольшом экране ноутбука, на большом мониторе и на iPad Mini, все эти девайсы у меня есть и хочется иметь единый настраиваемый интерфейс для них.
Mailr будет иметь gmail-совместимый режим через IMAP, чтоб можно было вернуться в любое время на gmail. Так как пока версия под мобильные телефоны не планируется, то этот режим будет тоже полезен, можно будет параллельно коннектиться к gmail привычным мобильным клиентом, если нужно. Кроме прочего с gmail за спиной проще начинать разработку и сконцентрироваться на удобном интерфейсе.
Многие функции из gmail нужно реализовать: удобные цепочки писем, метки, быстрый поиск, фильтры для сортировки входящей почты, хороший механизм схлопывания цитируемых писем, горячие клавиши, поддержка SSL…
Также будут дополнительные функции.
Объединение цепочек писем. Google хорошо находит соответствие писем и цепочек, но иногда его алгоритмы не работают:

Возможность вручную объединить цепочки – это выход в таких ситуациях.
Markdown для написания писем. Мне нравится Markdown и reStructuredText и мне бы хотелось писать письма используя эти текстовые языки разметки, после конвертации они выдают отличный для чтения HTML. Текущий редактор писем в gmail для меня очень неудобный.
Две панели. Это моя любимая функция :), две панели видно на скриншоте. Давно уже использую двухпанельный режим в своем текстовом редакторе VIM и мне уже не комфортно в однопанельных редакторах. Вторая панель расширяет обычно контекст, когда работаешь в первой. В будущем будет возможность отключить этот режим.
Настраеваемый интерфейс. Как говорил выше, мне нужен удобный интерфейс на разнообразных разрешениях экрана, темы и настройки интерфейса будут решать эту задачу.
Вся почта в одном табе. Я использую Chrome и мне нравится, что он открывает “Настройки”, “Скачанные файлы”, “Расширения” в новых вкладках, а не окнах (раньше использовал Firefox – он многое открывает в новых окнах). У меня весь серфинг интернета живет в одном окне браузера, а вся почта, в идеале, хочется, чтоб жила в одной вкладке (включая все аккаунты)
Простой backup. Это важно для Open Source продукта, чтоб была возможность взять все данные (аккаунты, фильтры, цепочки) и перенести с одной инсталяции на свою локальную или на сервер своего проверенного друга-гика.
Следующие версии
Когда можно будет использовать Mailr c gmail в качестве IMAP сервера, то дальше мне хочется уйти все таки от gmail и использовать свой email адрес. И, скорее всего, следующим шагом будет интеграция с Mailgun. Поднять свой правильный почтовый сервер с антиспам-фильтром – дело не самое легкое, с Mailgun будет проще, тем более они не хранят письма у себя.
Дальше много мыслей для продолжения: поддержка других IMAP серверов, множественные аккаунты в одном табе, PGP шифрование, списки рассылок для друзей…
Напоследок
Хочется в этом проекте использовать минимум зависимостей и непереусложнить с кодом, ведь потом все нужно будет поддерживать.
- Стек технологий:
- Python 3, werkzeug, jinja2, sqlalchemy, lxml;
- PostgreSQL с его крутыми типами данных и не только;
- lessjs, jquery на фронтенде.
Да, только jquery – из-за архитектурного решения. Мне больше нравится писать Python код, а JavaScript хочется очень минимизировать, поэтому вместо модного REST и рендеринга на стороне клиента мне захотелось генерировать семантичный HTML на стороне сервера. Это полезно, например, для iPad Mini, в нем процессор слабее и памяти меньше, чем обычно на ноутбуках и десктопах. В будущем эта ситуация может измениться.
В этом проекте еще нужно многое придумать, многое реализовать, многое оптимизировать. В последнее время я занимался им очень интенсивно, но мой отпуск заканчивается и нужно возвращаться к работе, то есть времени на проект будет намного меньше. Очень хочется его довести до стадии, чтоб заменить наконец gmail :).
Open Source – это круто и мне всегда хотелось отдать дань этому сообществу. Если задуманное мной в этом email клиенте удастся реализовать и получится хороший продукт, то это будет отличный вклад.
P.S.
Статья была на хабре, но им не понравилась ссылка на демо %).
- Примеры с цепочками писем, которые зацепили:
- Thunderbird и Thunderbird Conversations;
- Geary – gmail-подобный десктопный клиент;
- fastmail.fm – платная почта, которая какое-то время была под Opera Software.
И, конечно, смотрел на mailpile.is, но они пошли странным путем.